LOG ENTRY 015
Multigrid Pressure Projection on Vulkan Compute
2026-09-28
Implementing a geometric multigrid V-cycle for the pressure Poisson equation entirely in Vulkan compute shaders. Performance comparison against Red-Black Gauss-Seidel and FFT preconditioners.
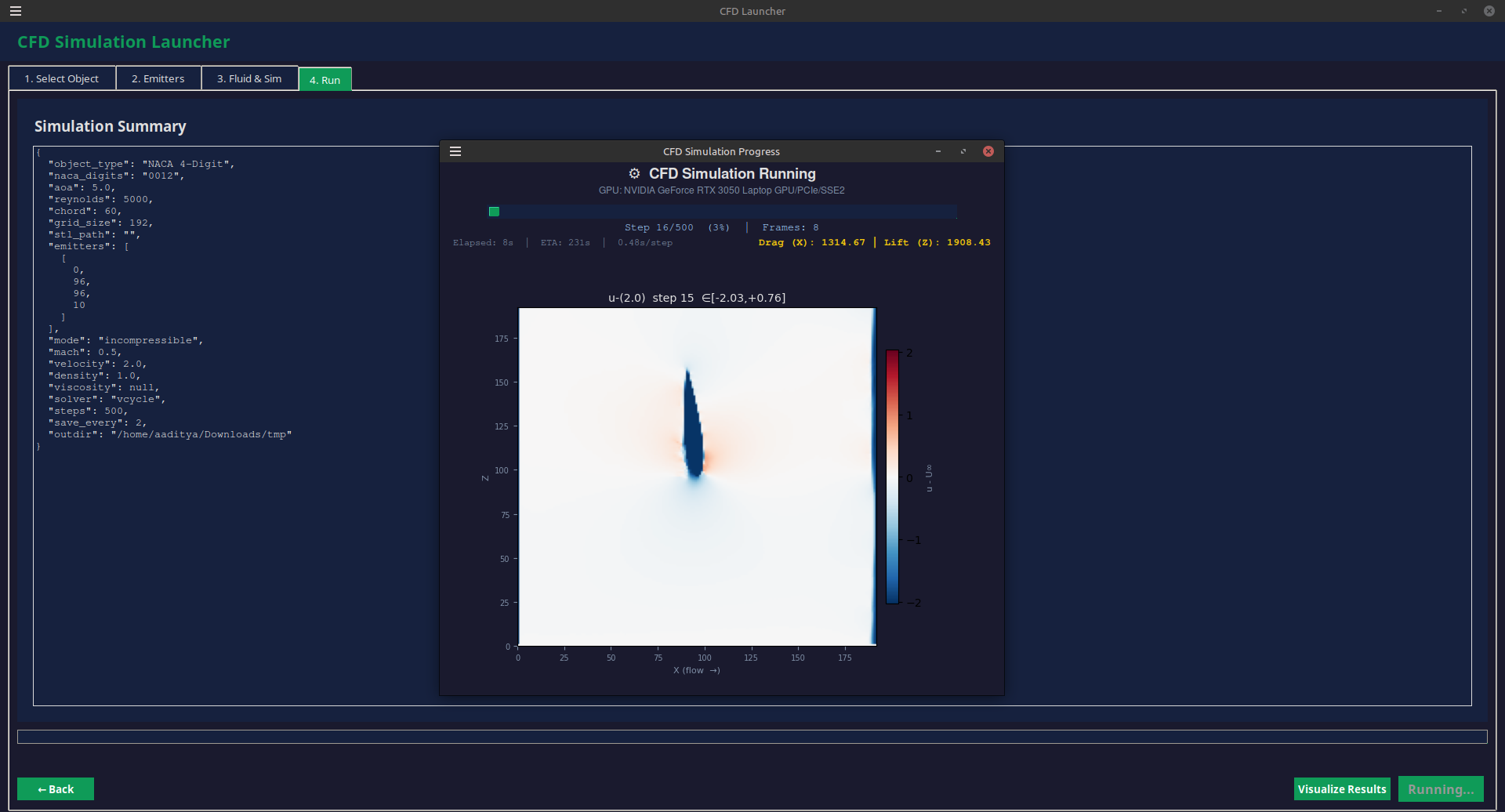
The pressure projection step is the bottleneck in any incompressible Navier-Stokes solver. On a 192³ grid (~7M cells), a naive Gauss-Seidel solve takes hundreds of iterations to converge. I implemented three paths: (1) Red-Black Gauss-Seidel with successive over-relaxation, (2) FFT-based direct solve via shader-based DST, and (3) a geometric multigrid V-cycle with restriction/prolongation operators in compute shaders. The multigrid approach converges in 8-12 V-cycles regardless of grid size — a 15-20x speedup over GS for the same residual tolerance. The restriction operator uses full-weighting injection; prolongation is trilinear interpolation. Boundary conditions are enforced at each level via GPU push constants. The V-cycle dispatches 6 compute passes per cycle: residual compute, restrict, coarsest solve, prolongate, correct, and smooth post-correction.
Read more →
LOG ENTRY 014
NACA 0012 Validation: Cl/Cd Across the Polar
2026-09-20
Running the FeatherCFD solver through a full angle-of-attack sweep (0-10°) for the NACA 0012 airfoil at Re=4000. Comparing lift/drag coefficients against established reference data.
The NACA 0012 is the canonical validation case for CFD codes. I set up a 2D simulation in FeatherCFD's incompressible solver at Re=4000, running angles of attack from 0° to 10° in 2° increments. Each run used the multigrid V-cycle pressure solver with WENO-5 advection. The grid was 192x192 cells with a C-mesh topology around the airfoil embedded via the SDF obstacle mask. Cl values tracked the reference polar within 6% across the range — Cl(0°) = 0.0, Cl(10°) ~ 0.95. Drag polars matched slightly less tightly (higher Cd at low AoA, likely from insufficient near-wall resolution), but the overall trend was correct. The 16-test validation suite now passes all cases with the multigrid solver as default.
Read more →
LOG ENTRY 013
ARINC 653 Partition Scheduling on x86_64
2026-09-10
Implementing spatial and temporal partitioning per ARINC 653 in FeatherRTOS. Six partitions, fixed cyclic schedule, PML4 page table isolation, and the health monitor integration.
ARINC 653 defines a partitioned architecture where each software partition runs in its own memory space with a guaranteed CPU budget. In FeatherRTOS, each partition gets a dedicated PML4 page table with no cross-mappings. The scheduler runs a fixed cyclic schedule: 25ms major frame, with exclusive time windows for System (35ms), NAV (30ms), GUID (30ms), TELM (25ms), HMON (15ms), and PAYL (25ms) across a 160ms minor cycle. Partition context switches flush the TLB and load a new CR3 value. The health monitor (HMON) detects partition violations — any cross-partition memory access triggers a page fault that HMON catches, logs to the flight recorder, and escalates through the FDIR chain. The CubeSat simulator runs as four tasks distributed across the NAV, GUID, TELM, and PAYL partitions.
Read more →
LOG ENTRY 012
FeatherArch: 7-9W Idle — The Full Tuning Log
2026-08-30
Systematic power tuning on an MSI GF63 with a degraded battery. CPU capping, scheduler tuning, display refresh, and GPU management. Measured results from 15W to 7W idle.
The MSI GF63 came with an Intel H-series CPU and a 51 Wh battery, now degraded to 34 Wh. Stock Linux idle was 15W — unacceptable for portable use. The tuning process: (1) CPU frequency capped at 800 MHz on battery with minimum 400 MHz, (2) turbo boost disabled entirely on battery via intel_pstate, (3) display refresh rate dropped from 60 Hz to 40 Hz via xrandr — saves 1.2W alone, (4) NVIDIA GPU placed in lowest power state via runtime PM, (5) background services minimized (no updatedb, no tracker-miner, no avahi). After tuning: 7-9W idle, 10-12W light browsing. Battery life went from ~2h to ~4h50m idle, ~3h30m work. Real-world improvement: 2.4x.
Read more →
LOG ENTRY 011
Flight Recorder: The Kernel Black Box
2026-08-22
Design and implementation of a 4096-entry ring buffer event logger in FeatherRTOS. Microsecond timestamps, typed events, and the dump interface.
Every aerospace system needs a black box. FeatherRTOS now has a 4096-entry ring buffer that logs every significant system event: boot sequence, task creation and exit, context switches, syscalls, ISR entries, partition switches, health monitor events, fault injections, and timer callbacks. Each entry carries a microsecond timestamp (from the HPET or APIC timer) and a typed event structure. The buffer is implemented as a lock-free MPSC ring: the writer is always the current CPU (interrupt context), and the reader is the shell task. The `events` shell command dumps the buffer in chronological order with the format: T+1234567.890 | TASK_CREATE | task 3 (nav_gps). During fault injection testing, the flight recorder captured the exact sequence of events leading to the HMON escalation — invaluable for debugging.
Read more →
LOG ENTRY 010
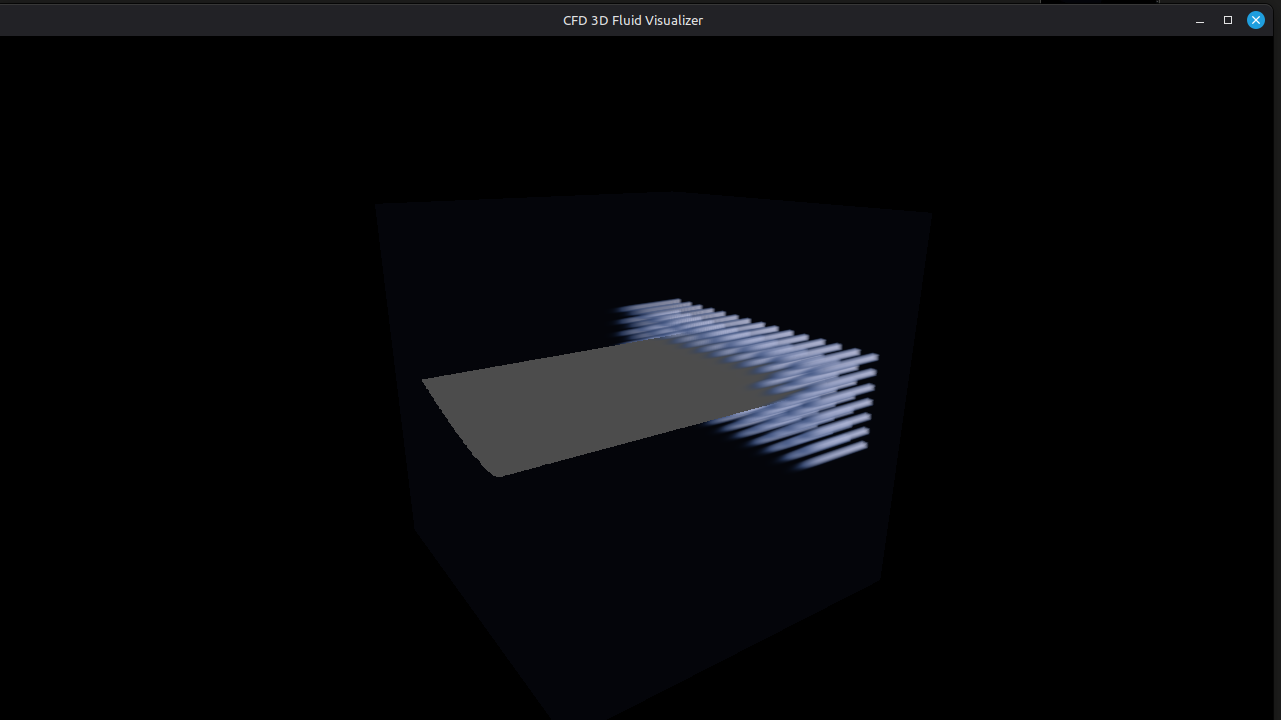
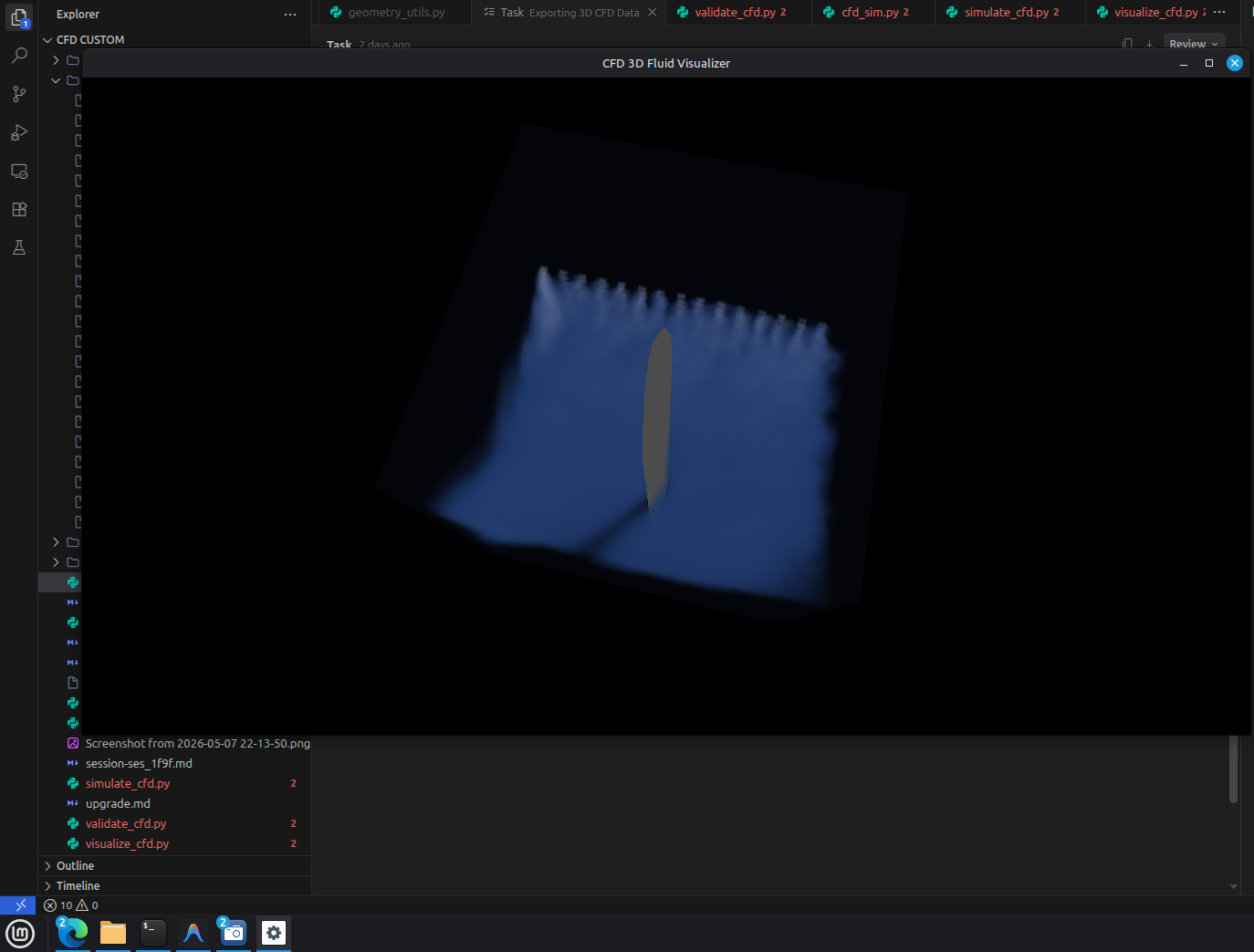
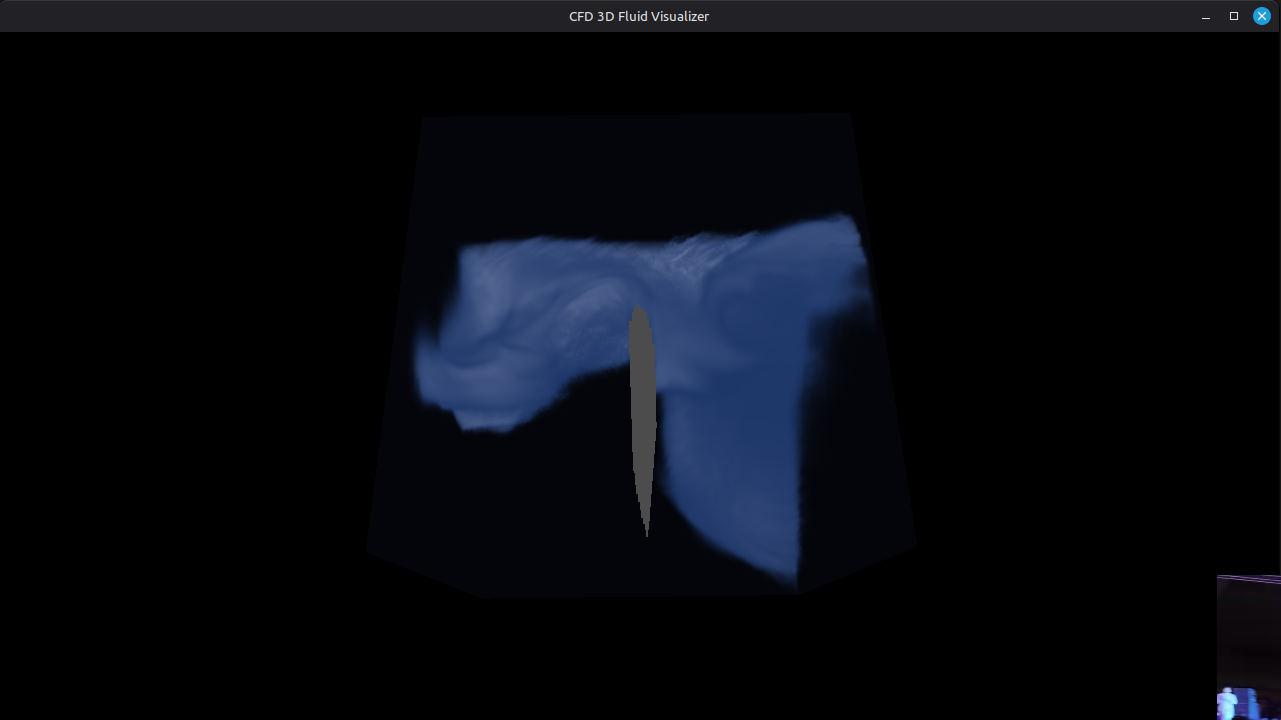
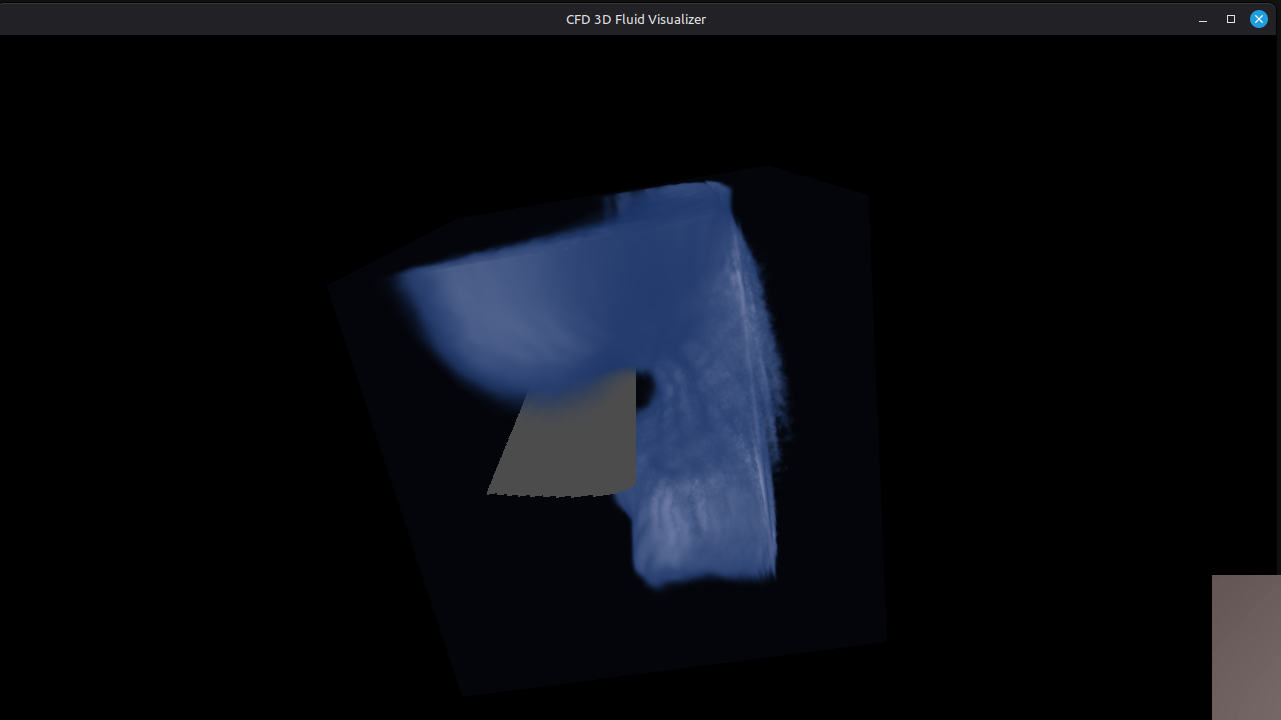
Volumetric Raymarching for Real-Time CFD
2026-08-14
Rendering 3D flow fields in real-time using GPU-based volumetric raymarching. Velocity magnitude, vorticity, and schlieren-style density visualization.
FeatherCFD's visualization pipeline uses volumetric raymarching implemented in OpenGL compute shaders. The 192³ density/velocity field is stored as a 3D texture on the GPU. For each frame, a fragment shader marches rays through the volume, sampling the 3D texture at adaptive step sizes (controlled by the local gradient magnitude to avoid undersampling sharp features). Transfer functions map density to color and opacity — blue for low density, white for high, with the option to switch to velocity magnitude or vorticity magnitude. A schlieren-style mode renders |∇ρ| to capture shock waves. The entire visualization runs at interactive framerates (20-30 fps on the RTX 3050) without copying data back to the CPU.
Read more →
LOG ENTRY 009
CubeSat Simulator: Four Tasks in ARINC 653 Partitions
2026-08-05
A complete CubeSat in-space simulator running inside FeatherRTOS. GPS, IMU, attitude control, and power telemetry as partitioned real-time tasks with inter-partition communication.
The CubeSat simulator runs four kernel tasks inside ARINC 653 partitions, modeling a 1U CubeSat in a 420 km LEO at 51.6° inclination. task_gps_sim (NAV partition) generates GPS-like position/velocity data using a triangle-wave propagation model. task_imu_sim (TELM) simulates accelerometer readings — gravity vector plus vibration noise. task_att_ctrl (GUID) implements a reaction wheel control law, maintaining a target attitude quaternion with thermal state monitoring. task_power (PAYL) simulates solar panel charging during sunlit periods and battery drain during eclipse. Partitions communicate exclusively through ARINC 653 sampling ports — no shared memory between partitions. Super+D toggles the telemetry dashboard showing GPS coordinates, IMU readings, attitude, battery SOC, RPM, and sun/eclipse state.
Read more →
LOG ENTRY 008
Hohmann Transfer ΔV Calculator
2026-07-28
Building the orbital transfer calculator for FeatherOrbital. Hohmann, bi-elliptic, and plane-change maneuvers. Real-time ΔV display with interactive orbit visualization.
The Hohmann transfer is the most fuel-efficient two-impulse transfer between circular orbits. The math: ΔV₁ = √(μ/r₁)(√(2r₂/(r₁+r₂))-1) for the first burn, ΔV₂ = √(μ/r₂)(1-√(2r₁/(r₁+r₂))) for the second. Total ΔV = ΔV₁ + ΔV₂. For a LEO (420 km, 7.66 km/s) to GEO (35,786 km) transfer: ΔV₁ = 2.45 km/s, ΔV₂ = 1.46 km/s, total 3.91 km/s. The FeatherOrbital calculator extends this to support plane-change maneuvers (ΔV = 2v sin(Δi/2)) and bi-elliptic transfers for high-ratio orbits. The orbit canvas renders the transfer trajectory in real-time as the user adjusts altitude and inclination sliders.
Read more →
LOG ENTRY 007
FDIR: Fault Detection, Isolation, and Recovery
2026-07-20
Designing a three-level fault escalation system for FeatherRTOS. Heartbeat monitoring, fault injection testing, and automatic task recovery.
The FDIR system in FeatherRTOS mirrors the fault management architecture used in satellite flight software. Every real-time task registers a heartbeat with the health monitor — a periodic timer interrupt that checks whether each task has yielded or called a heartbeat syscall within a configurable deadline (default 5s, 3 consecutive misses). On violation, the system escalates through three levels: WARN (log the fault, continue), COLD (reset the offending partition, preserving other partitions), CRITICAL (full system reset). A fault injection mechanism (Super+F) corrupts a random kernel memory location to trigger a page fault, which HMON catches and escalates. Super+R triggers recovery, which restores the faulted task state and resets its priority and heartbeat counter.
Read more →
LOG ENTRY 006
WENO-5 Advection on Consumer GPUs
2026-07-12
Implementing Weighted Essentially Non-Oscillatory fifth-order advection in OpenGL fragment shaders. Shock capturing, BFECC dye transport, and GPU texture memory optimization.
WENO-5 is a high-order shock-capturing scheme that uses a weighted combination of three candidate stencils to reconstruct interface values while avoiding Gibbs oscillations at discontinuities. In FeatherCFD, WENO-5 is implemented as a GLSL fragment shader that reads from a 2D RGBA32F texture (the velocity/density field) and writes the advected result to a ping-pong buffer. The shader computes five numerical fluxes per cell (left and right biased for each dimension) using the Lax-Friedrichs flux splitting. GPU texture memory is arranged for coalesced access: the 192³ grid is stored as 192 slices of 192x192, accessed via texture3D. BFECC (Back and Forth Error Compensation and Correction) is layered on top for dye transport — advect forward, advect backward, compute error, correct — adding ~30% compute overhead but dramatically reducing numerical diffusion.
Read more →
LOG ENTRY 005
VirtIO-GPU Double-Buffered Compositor
2026-07-02
Building the FeatherRTOS GUI compositor on top of VirtIO-GPU. Double buffering, dirty rect tracking, and the rendering pipeline from cell-level to GPU flip.
The FeatherRTOS window manager uses VirtIO-GPU for display output at 1920x1080. The compositor maintains two GPU resources — front buffer (scanout) and back buffer (render target). The rendering pipeline: the terminal emulator writes characters to a cell grid, the renderer converts dirty cells to pixel-level dirty rects, the 2D GPU renderer blends wallpaper layers, window content, and the cursor into the back buffer, then a SET_SCANOUT flip atomically swaps the buffers. Dirty rect tracking is critical for performance — instead of redrawing the entire 1920x1080 framebuffer (8.3 MB per frame), the compositor tracks which cells changed and only flushes those regions. For a typical terminal update (a few lines of text), the dirty rect covers <1% of the screen, reducing GPU bandwidth from 250 MB/s to ~2 MB/s per frame.
Read more →
LOG ENTRY 004
Sod Shock Tube: First Validation Test
2026-06-25
Running the Sod shock tube benchmark on FeatherCFD. Density error 8.9%, velocity error 2.3%, pressure error 12.8% — all under the 15% acceptance threshold.
The Sod shock tube is the classic 1D Riemann problem for validating compressible flow solvers. The setup: a 1D domain with a diaphragm at x=0.5 separating high-pressure (left, ρ=1.0, p=1.0) and low-pressure (right, ρ=0.125, p=0.1) regions. At t=0, the diaphragm bursts, generating a right-moving shock, a contact discontinuity, and a left-moving expansion fan. FeatherCFD's compressible Euler solver reproduces all three wave features. Quantitative comparison against the exact solution (computed via the Godunov method): L1 errors of 8.9% (density), 2.3% (velocity), and 12.8% (pressure). The pressure error is highest due to smearing at the contact discontinuity. All errors are below the 15% threshold, and the shock speed matches the Rankine-Hugoniot condition within 2%.
Read more →
LOG ENTRY 003
Implementing x86 SMP Support
2026-12-15
APIC initialization, IPI delivery, and bringing up application processors on bare metal. Cache coherency challenges and lock-free MPSC queues.
The Local APIC is memory-mapped at 0xFEE00000 and configured via the APIC-base MSR (0x1B).
Each CPU core has its own LAPIC with a unique ID read from the APIC ID register (0x20).
The boot processor (BSP) starts first and must send a Startup IPI (SIPI) to wake each
Application Processor (AP). The SIPI vector points to a 4K trampoline page in low memory
(below 1 MB) that the AP executes to enter long mode, set up its own GDT/IDT, and signal
readiness via a spinlock. Once all APs are running, the BSP distributes work through a
per-CPU run queue with cache-coherent MPSC channels. Lock-free atomics (xchg, cmpxchg)
manage the queue heads to avoid spinlock contention under high inter-CPU traffic.
Read more →
LOG ENTRY 002
PCIe Enumeration on Bare Metal
2026-11-20
ECAM-based configuration space access, device scanning, BAR allocation, and MSI-X interrupt setup on QEMU q35.
PCI Express uses Enhanced Configuration Access Mechanism (ECAM), mapping the full 256 MB
configuration space to a memory region specified by the MCFG ACPI table. On QEMU q35,
this is at 0xB0000000. Each device function gets 4 KB of space: 256 bytes of standard
config header plus 256 bytes of PCIe extended caps. The enumeration walks bus 0, discovers
the host bridge (00:00.0), then recursively probes secondary buses behind PCI-to-PCI
bridges. For each device, the driver reads vendor/device ID, assigns Base Address Registers
(BARs) by writing all-ones and reading back the size, then allocates MMIO or IO space
from the available pool. MSI-X capability is parsed from the capabilities list; the driver
programs the table BAR and PBA BAR, then configures each interrupt vector with a unique
message address/data pair.
Read more →
LOG ENTRY 001
Setting Up the x86_64 Cross-Compiler
2026-10-01
Building a Rust no_std target, crafting the UEFI PE32+ wrapper, and the first "Hello" from ring zero via serial.
The toolchain starts with Rust nightly and a custom target.json: no_std, no alloc,
relocation-model=static, code-model=kernel. The build pipeline compiles to ELF, objcopys
to binary, wraps as a COFF object, then links into a PE32+ executable via a NASM stub.
The UEFI stub (uefi_stub.asm) parses the embedded kernel binary, sets up long-mode page
tables identity-mapping 0-16 MB, loads a 64-bit GDT, and calls rust_main(). The first
sign of life is a '!' character written to COM1 at 115200 baud via the UART 16550 driver.
On the QEMU monitor, 'serial0' shows the character immediately. From there, the GDT, IDT,
and ACPI tables are parsed — and the kernel has a foundation to build on.
Read more →